Cross-Linguistic Colexifications
An Introduction

Agenda 2024
- Colexifications
- CLICS
- Lexibank
- Partial Colexifications
- Next Big Things
Colexifications
Colexifications
Definition
A given language is said to colexifiy two functionally distinct senses if, and only if, it can associate them with the same lexical form. (François 2008: 170)
Colexifications
Simple Definition
Colexification is a cover term for polysemy and homophony. Polysemy points to words with multiple senses due to semantic change. Homophony points to different words that sound alike due to sound change or borrowing.
Colexifications
Advantages
- Polysemy and homophony are at times hard to distinguish.
- Definitions for polysemy and homophony are ontological in nature, requiring us to know the full history of words
- We need epistemological terms that cover initial findings that can be obtained in a straightforward manner.
CLICS

CLICS
CLICS 1.0 (List et al. 2014)
- First attempt to provide a simple interface to browse colexification networks.
- Initial network visualization component added later to the very first PhP version.
- Still available at https://clics.lingpy.org/
- Just about 300 languages and about 1200 concepts.
CLICS
CLICS 2.0 (List et al. 2018)
- Expanding upon the idea of aggregating datasets along the lines of Concepticon and Glottolog (compiled as CLDF dataset).
- Provides a first workflow for data aggregation with data from 15 datasets.
- Contains some 1200 languages with about 1500 concepts (but lower coverage).
CLICS
CLICS 3.0 (Rzymski et al. 2020)
- Finalizing the idea of aggregating datasets by showing how data from 30 datasets can be aggregated and combined to form the new CLICS database.
- Now with more than 2000 languages and about 2000 concepts (but much sparser).
- Available (still) at https://clics.clld.org
CLICS
CLICS 4.0 (Tjuka et al. in prep.)
- Will increase datasets (to about 50, maybe more).
- Will decrease concepts and languages, aiming for more coverage.
- An early version can be found in Tjuka (2024) and Tjuka et al. (2024).
CLICS
How to Create Your Own CLICS?
- Tutorials showing how one can create one's own CLICS collection from a CLDF dataset were published in 2022 (List 2022a and List 2022b and List 2022c).
- With little prerequisites, anybody following these tutorials can create their own colexification networks and host them online.
- Code and data can be found at https://github.com/cldf/clicsviz
Lexibank

Lexibank
Background
- Lexibank (List et al. 2022, https://lexibank.clld.org) is a repository of lexical data (wordlists) aggregated from more than 100 distinct datasets.
- Lexibank builds on CLDF (Forkel et al. 2018, https://cldf.clld.org) to facilitate data aggregation.
- Lexibank extends CLDF by providing its own routines to lift data from raw to standardized form.
Lexibank
Standards in Lexibank
- Concepticon (List et al. 2024, https://concepticon.clld.org) is used to link all common concepts in the individual concept lists of individual datasets to a common reference catalog.
- Glottolog (Hammarström et al. 2024, https://glottolog.org) is used to map all languages to common language codes.
- CLTS (List et al. 2022, https://clts.clld.org) is used to unify the transcriptions in the data standardized by the Lexibank workflow, using a universal phonetic transcription system that corrects for ambiguities in the IPA.
Lexibank
Colexifications as Features
- Lexibank illustrates how colexifications can be computed from large aggregated datasets by handling them as features that can also be plotted on a map.
- Code is shown for about 30 lexical features, but many more could be computed.
Lexibank
Arm/Hand and Leg/Foot Colexifications
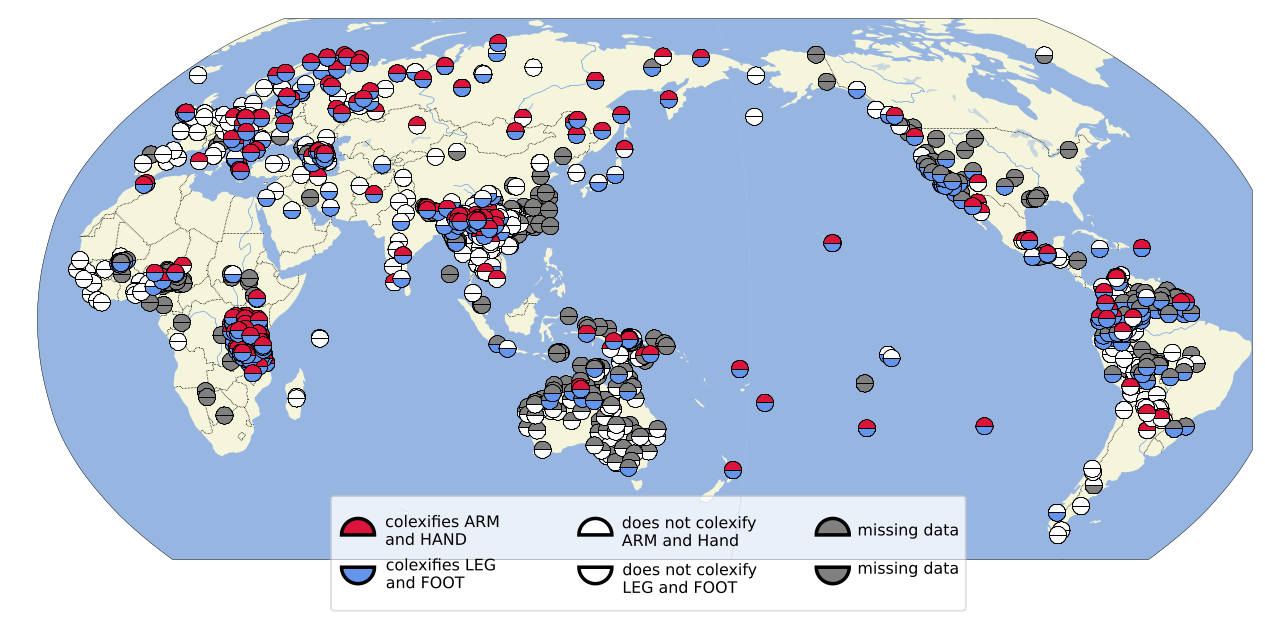
Lexibank
Partial Colexifications as Features
- Partial colexifications refer to those cases of colexifications where only parts of words are shared across words.
- List (2023) takes inspiration from Urban (2011) in distinguishing affix colexifications (where one word recurs in another word in prefix or suffix position) from overlap colexifications (where two words share a common sound sequence).
- Computation of these features is less straightforward, as is their interpretation.
Lexibank
Common Substrings

Lexibank
Partial Colexifications

Lexibank
Lexibank 2.0 (Blum et al. in prep.)
- Lexibank 2.0 will increase the number of datasets again by about 20 more datasets that will be included.
- Lexibank 2.0 will also improve the workflow and present now all data, even duplicates, but allowing for efficient filters.
Partial Colexifications

Partial Colexifications
Introduction
- Colexification refers to words with multiple senses.
- Complex words may however also share morphemes.
- But shared morphemes are difficult to identify, especially in computational approaches.
- List (2023) builds on both Urban (2011) and François (2008) to explore how well partial colexification relations between words can be explored automatically.
Partial Colexifications
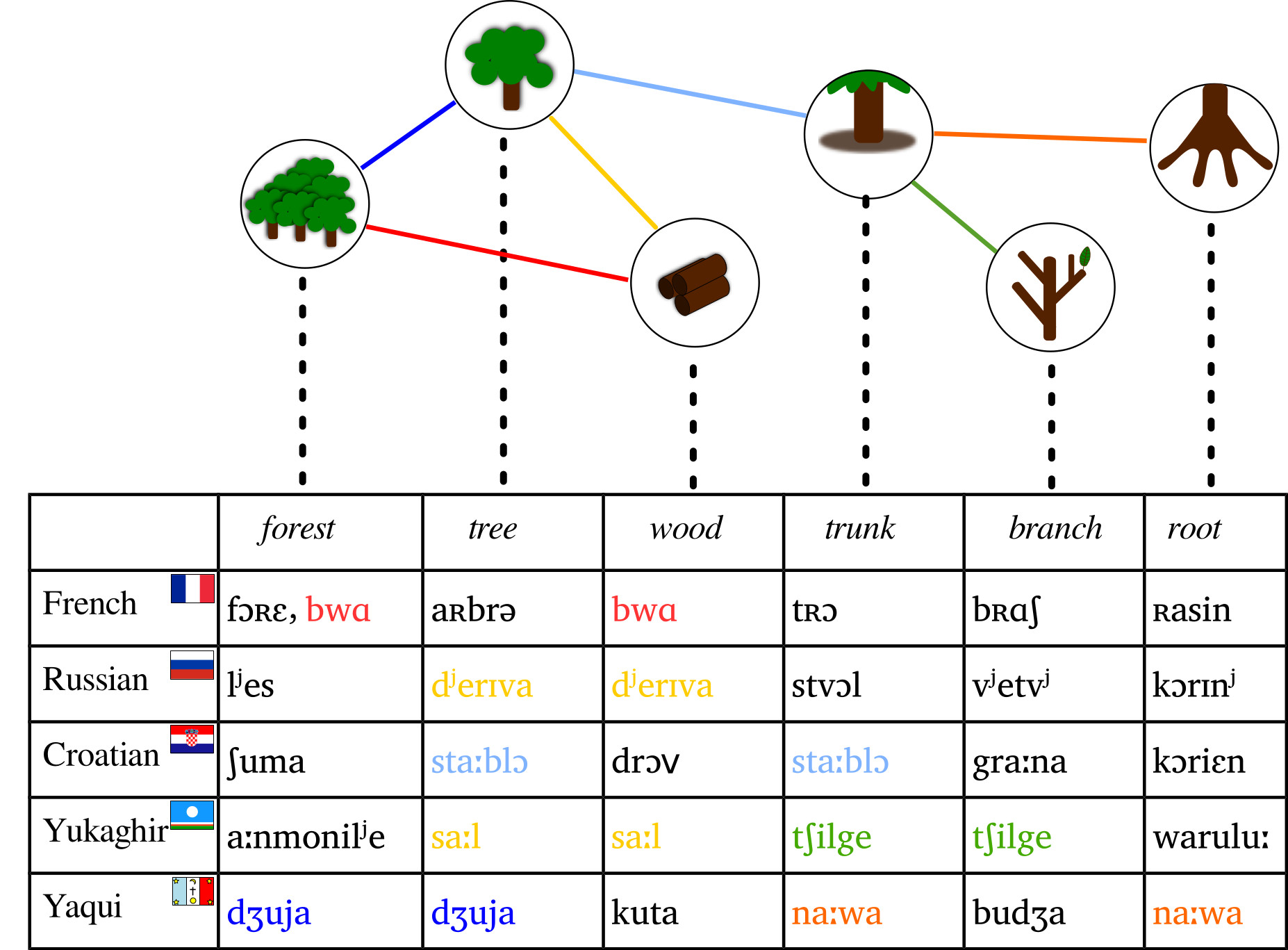
Examples

Partial Colexifications
Algorithms
- List (2023) presented initial algorithms that can be used to infer partial colexifications (affix colexification and overlap colexification) in standardized CLDF datasets.
- The method for the inference of affix colexifications yields directed networks.
- The method for overlap colexifications yields undirected networks.
Partial Colexifications
Affix Colexification Networks (1)
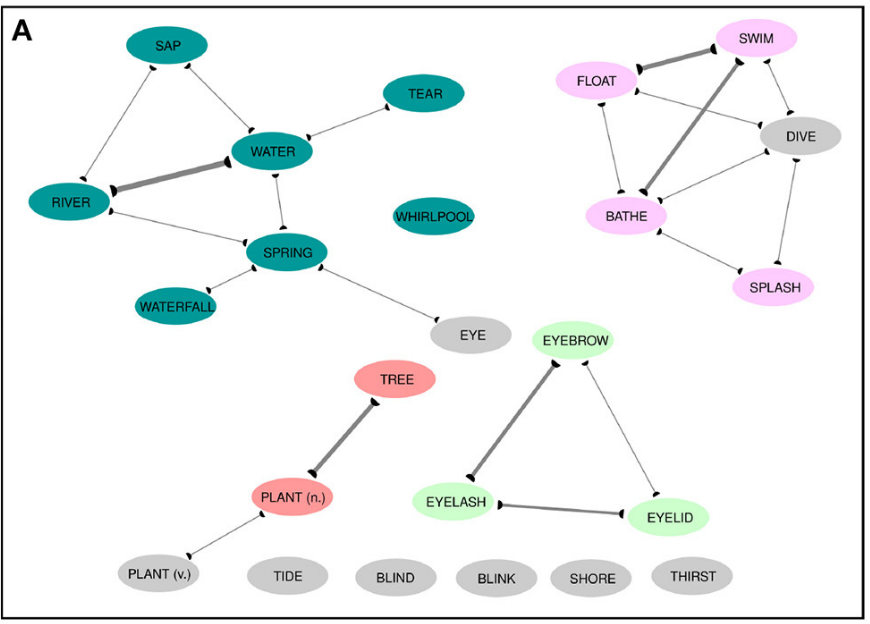
Full colexification network of IDS data
Partial Colexifications
Affix Colexification Networks (2)
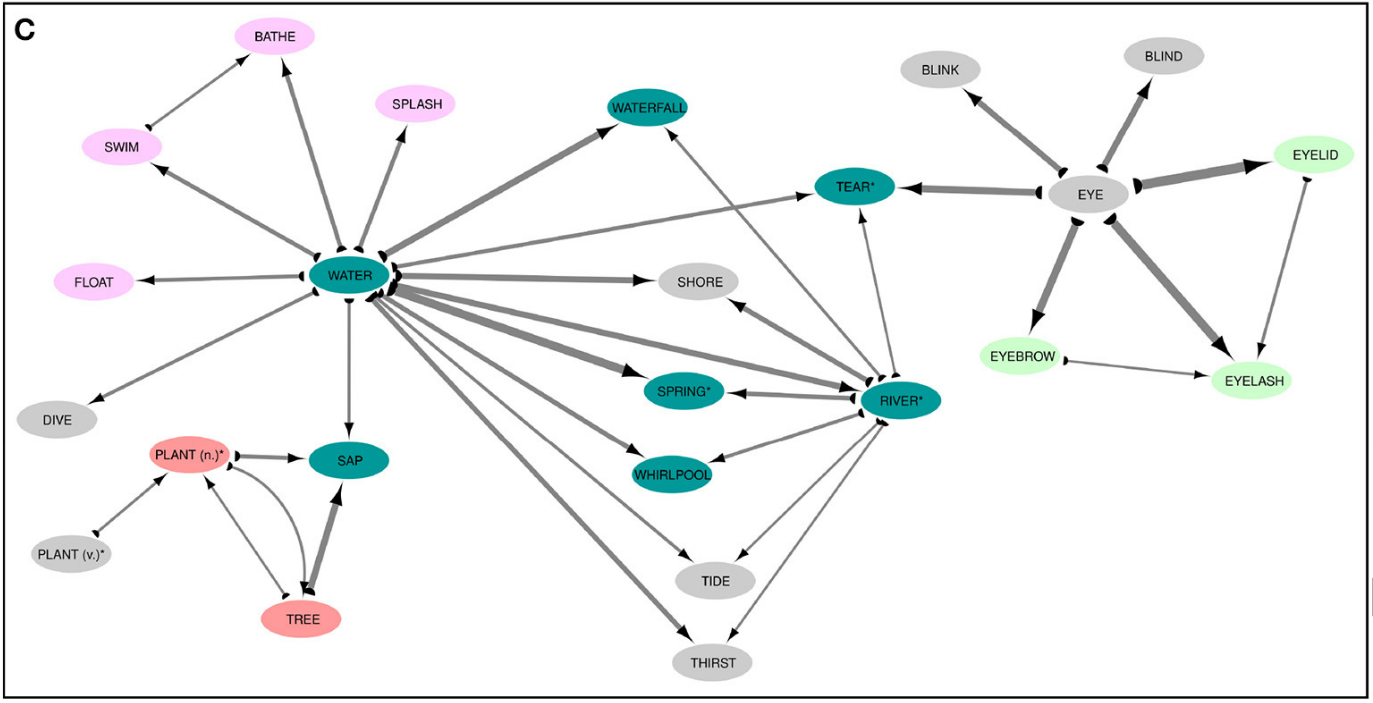
Affix colexification network of IDS data
Partial Colexifications
Summary
- Partial colexifications have not been fully explored so far.
- While full-fledged network approaches should be taken with care, due to the increase in noise, targeted analyses (as presented in Tjuka and List 2024 for body-object colexifications or in Norcliffe and Majid 2024 for perception verbs) may offer interesting new insights into lexical typology across different domains.
The Next Big Things
Exploring Directionality of Semantic Shift and Colexification
- Following Bocklage et al. (2024), who compare partial colexifications against the DatSemShift by Zalizniak et al. (2024), we need more analyses that investigate the nature of partial colexifications.
The Next Big Things
Fast Colexification Analyses with SQLite
- Shcherbakova and List (2023) pioneered in showing how targeted colexifications can be computed with pure database techniques, making computation faster and more transparent.
- Lexibank 2.0 will also provide such possibilities (Blum et al. in preparation).
- They offer scholars more freedom to explore colexifications on their own.
The Next Big Things
New Data for Colexification Studies
- Colexification studies are so far mostly limited to lexical typology.
- We could easily expand them to other domains, including object naming (Snodgrass and Vanderwart 1980), or parallel corpus data (Liu et al. 2023).
The Next Big Things
Improving Morpheme Segmentation and Annotation
- Finding morphemes in monolingual wordlists is one of the key steps for identifying colexifications beyond the word.
- Improved algorithms that automate this task could turn out to be game changers for large-scale analyses.
- Improved annotation methods to code colexifications and morphemes in wordlists would make our work more transparent.
Danke für ihre Aufmerksamkeit!